Task Definition
Given an issue title and its initial description, predict the set of functions and classes that were modified by the fixing pull request.
- Input: issue title + initial body
- Output: function/class nodes
- Granularity: repository-level

A high-fidelity benchmark for repository-level bug localization, built for graph neural networks and grounded in real-world GitHub issues.
Results are reported on nine representative repositories under the GREPO evaluation protocol, using issue title and initial description as input and Hit@K as the primary metric.
Leaderboard
Scores are mean Hit@K across nine representative repositories. Use the filters to compare GNNs, LLM baselines, and retrieval methods.
| Rank | Model | Type | Avg Rank | Hit@1 | Hit@5 | Hit@10 | Hit@20 | Notes |
|---|---|---|---|---|---|---|---|---|
| Loading leaderboard data... | ||||||||
Performance Signature
A smooth profile of Hit@K metrics across Eval9.
Repository View
Compare model performance within a single repository. Select a repository and metric to explore detailed results.
Metric: Hit@10
Visuals
More refined views for model comparison, performance patterns, and the benchmark landscape.
Repository-level delta between two models.
Positive values indicate Model A outperforms Model B.
Average Hit@K values across Eval9.
Grouped by model family.
Selected model from the leaderboard is highlighted.
Benchmark
GREPO evaluates repository-level bug localization with a strict leakage-safe input policy and graph-native supervision.
Given an issue title and its initial description, predict the set of functions and classes that were modified by the fixing pull request.
Each repository is represented as a temporal, heterogeneous graph with explicit structural and semantic relationships.
Mean Hit@K across all test issues, calculated against full ground-truth node sets.
Dataset
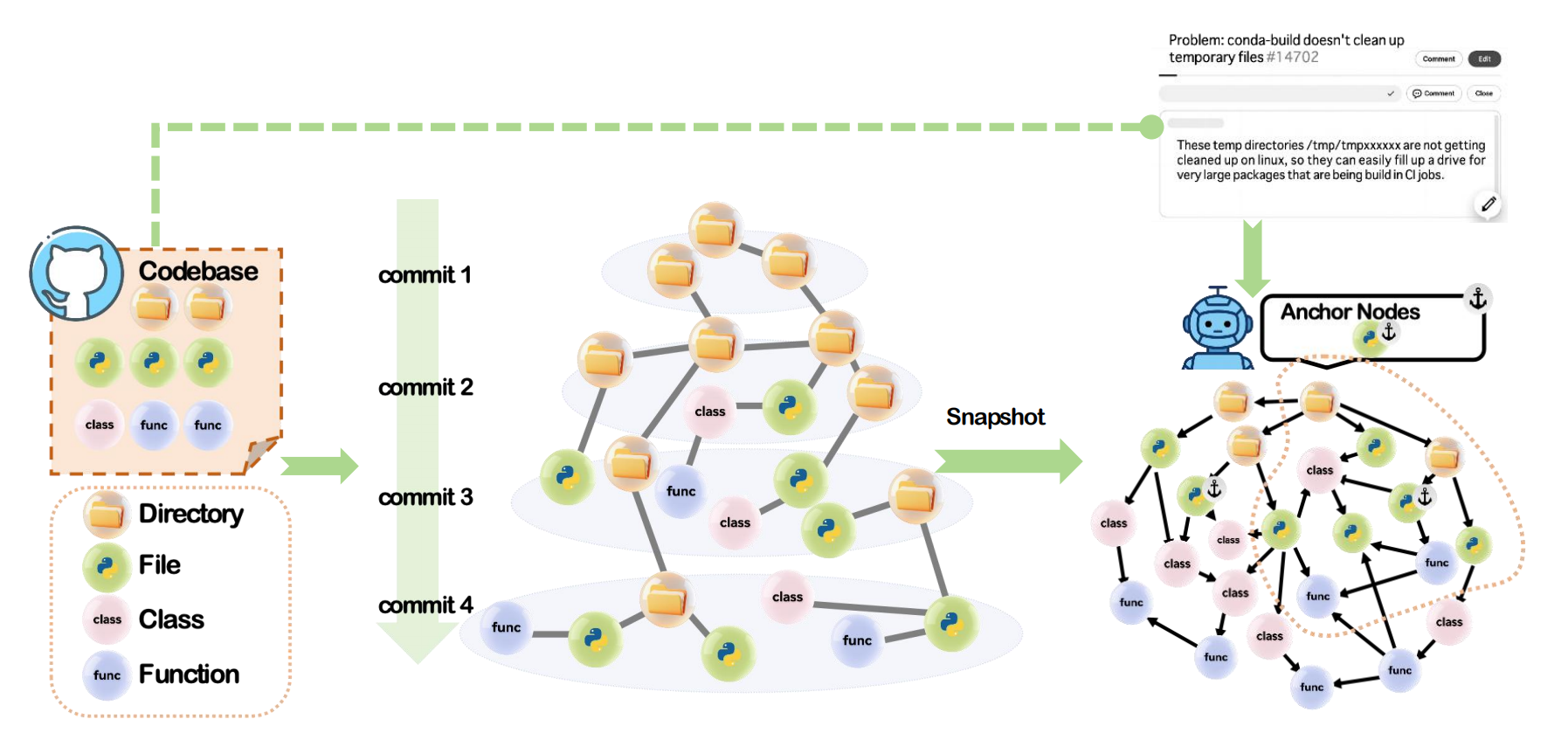
GREPO is built from real-world GitHub repositories and issues, with an incremental graph pipeline designed for scale.
Build a single temporal graph with per-commit lifespans, updating only changed files to keep construction efficient.
Link issues to merged PRs via closing keywords, and use only leakage-safe issue text as model input.
Encode node text with embeddings and compute query-node similarity to provide lightweight, transferable signals for GNNs.
Methods
The GREPO pipeline combines semantic anchors, temporal signals, and graph neural reranking for multi-hop localization.
Issue reports are rewritten into structured queries and entities to retrieve high-quality anchor nodes before message passing.
An issue-conditioned temporal retriever ranks nodes based on recent co-change history without leaking future information.
A query-aware GNN scores nodes inside the extracted subgraph to deliver final rankings in Hit@K metrics.
Resources
Open-source code, data, and ready-to-run commands for benchmarking.
Training, evaluation, and dataset tooling for the full benchmark.
Open GitHub RepositoryDownload the benchmark dataset and graph artifacts.
Open Dataset PageUse the included command templates to train and evaluate models.
See examples/commands in the repoUse the leaderboard as a reference, then plug in your own retrieval or GNN model to test against the same Eval9 protocol.